Gridded Datasets#
import numpy as np
import xarray as xr
import holoviews as hv
from holoviews import opts
hv.extension('matplotlib')
opts.defaults(opts.Scatter3D(color='Value', cmap='fire', edgecolor='black', s=50))


In the Tabular Data guide we covered how to work with columnar data in HoloViews. Apart from tabular or column based data there is another data format that is particularly common in the science and engineering contexts, namely multi-dimensional arrays. The gridded data interfaces allow working with grid-based datasets directly.
Grid-based datasets have two types of dimensions:
they have coordinate or key dimensions, which describe the sampling of each dimension in the value arrays
they have value dimensions which describe the quantity of the multi-dimensional value arrays
There are many different types of gridded datasets, which each approximate or measure a surface or space at discretely specified coordinates. In HoloViews, gridded datasets are typically one of three possible types: Regular rectilinear grids, irregular rectilinear grids, and curvilinear grids. Regular rectilinear grids can be defined by 1D coordinate arrays specifying the spacing along each dimension, while the other types require grid coordinates with the same dimensionality as the underlying value arrays, specifying the full n-dimensional coordinates of the corresponding array value. HoloViews provides many different elements supporting regularly spaced rectilinear grids, but currently only QuadMesh supports irregularly spaced rectilinear and curvilinear grids.
The difference between uniform, rectilinear and curvilinear grids is best illustrated by the figure below:
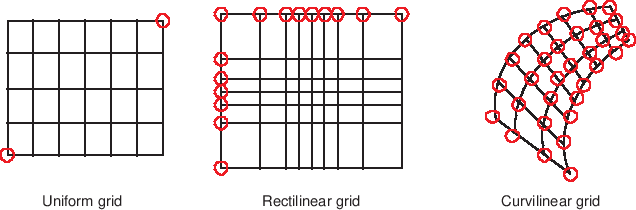
In this section we will first discuss how to work with the simpler rectilinear grids and then describe how to define a curvilinear grid with 2D coordinate arrays.
Declaring gridded data#
All Elements that support a ColumnInterface also support the GridInterface. The simplest example of a multi-dimensional (or more precisely 2D) gridded dataset is an image, which has implicit or explicit x-coordinates, y-coordinates and an array representing the values for each combination of these coordinates. Let us start by declaring an Image with explicit x- and y-coordinates:
img = hv.Image((range(10), range(5), np.random.rand(5, 10)), datatype=['grid'])
img

In the above example we defined that there would be 10 samples along the x-axis, 5 samples along the y-axis and then defined a random 5x10 array, matching those dimensions. This follows the NumPy (row, column) indexing convention. When passing a tuple HoloViews will use the first gridded data interface, which stores the coordinates and value arrays as a dictionary mapping the dimension name to a NumPy array representing the data:
img.data
{'x': array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),
'y': array([0, 1, 2, 3, 4]),
'z': array([[0.11475007, 0.8886772 , 0.35578193, 0.15199495, 0.87791507,
0.37210861, 0.21596753, 0.70888964, 0.78590232, 0.64642225],
[0.96755528, 0.96145783, 0.09758068, 0.48751456, 0.36819159,
0.92486398, 0.69232212, 0.94161373, 0.11332585, 0.80232088],
[0.24936194, 0.17099133, 0.70818874, 0.88293882, 0.901649 ,
0.14171089, 0.44342657, 0.30564338, 0.81614251, 0.13749141],
[0.47257613, 0.05378833, 0.66811556, 0.08157941, 0.77842272,
0.01977987, 0.5088595 , 0.77920296, 0.9706746 , 0.98930903],
[0.40054224, 0.93062036, 0.84323285, 0.58706651, 0.40581688,
0.94888527, 0.17343138, 0.19185212, 0.60763529, 0.83432136]])}
However HoloViews also ships with an interface for xarray and the GeoViews library ships with an interface for iris objects, which are two common libraries for working with multi-dimensional datasets:
arr_img = img.clone(datatype=['image'])
print(type(arr_img.data))
try:
xr_img = img.clone(datatype=['xarray'])
print(type(xr_img.data))
except Exception:
print('xarray interface could not be imported.')
<class 'numpy.ndarray'>
<class 'xarray.core.dataset.Dataset'>
In the case of an Image HoloViews also has a simple image representation which stores the data as a single array and converts the x- and y-coordinates to a set of bounds:
print(f"Array type: {type(arr_img.data)} with bounds {arr_img.bounds}")
Array type: <class 'numpy.ndarray'> with bounds BoundingBox(points=((-0.5,-0.5),(9.5,4.5)))
To summarize the constructor accepts a number of formats where the value arrays should always match the shape of the coordinate arrays:
1. A simple np.ndarray along with (l, b, r, t) bounds
2. A tuple of the coordinate and value arrays
3. A dictionary of the coordinate and value arrays indexed by their dimension names
3. XArray DataArray or XArray Dataset
4. An Iris cube
Working with a multi-dimensional dataset#
A gridded Dataset may have as many dimensions as desired, however individual Element types only support data of a certain dimensionality. Therefore we usually declare a Dataset to hold our multi-dimensional data and take it from there.
dataset3d = hv.Dataset((range(3), range(5), range(7), np.random.randn(7, 5, 3)),
['x', 'y', 'z'], 'Value')
dataset3d
:Dataset [x,y,z] (Value)
This is because even a 3D multi-dimensional array represents volumetric data which we can display easily only if it contains few samples. In this simple case we can get an overview of what this data looks like by casting it to a Scatter3D Element (which will help us visualize the operations we are applying to the data:
hv.Scatter3D(dataset3d)

Indexing#
In order to explore the dataset we therefore often want to define a lower dimensional slice into the array and then convert the dataset:
dataset3d.select(x=1).to(hv.Image, ['y', 'z']) + hv.Scatter3D(dataset3d.select(x=1))

Groupby#
Another common method to apply to our data is to facet or animate the data using groupby operations. HoloViews provides a convenient interface to apply groupby operations and select which dimensions to visualize.
(dataset3d.to(hv.Image, ['y', 'z'], 'Value', ['x']) +
hv.HoloMap({x: hv.Scatter3D(dataset3d.select(x=x)) for x in range(3)}, kdims='x'))
Aggregating#
Another common operation is to aggregate the data with a function thereby reducing a dimension. You can either aggregate the data by passing the dimensions to aggregate or reduce a specific dimension. Both have the same function:
hv.Image(dataset3d.aggregate(['x', 'y'], np.mean)) + hv.Image(dataset3d.reduce(z=np.mean))

By aggregating the data we can reduce it to any number of dimensions we want. We can for example compute the spread of values for each z-coordinate and plot it using a Spread and Curve Element. We simply aggregate by that dimension and pass the aggregation functions we want to apply:
hv.Spread(dataset3d.aggregate('z', np.mean, np.std)) * hv.Curve(dataset3d.aggregate('z', np.mean))

It is also possible to generate lower-dimensional views into the dataset which can be useful to summarize the statistics of the data along a particular dimension. A simple example is a box-whisker of the Value for each x-coordinate. Using the .to conversion interface we declare that we want a BoxWhisker Element indexed by the x dimension showing the Value dimension. Additionally we have to ensure to set groupby to an empty list because by default the interface will group over any remaining dimension.
dataset3d.to(hv.BoxWhisker, 'x', 'Value', groupby=[])

Similarly we can generate a Distribution Element showing the Value dimension, group by the ‘x’ dimension and then overlay the distributions, giving us another statistical summary of the data:
dataset3d.to(hv.Distribution, 'Value', [], groupby='x').overlay()

Categorical dimensions#
The key dimensions of the multi-dimensional arrays do not have to represent continuous values, we can display datasets with categorical variables as a HeatMap Element:
heatmap = hv.HeatMap((['A', 'B', 'C'], ['a', 'b', 'c', 'd', 'e'], np.random.rand(5, 3)))
heatmap + hv.Table(heatmap)

Non-uniform rectilinear grids#
As discussed above, there are two main types of grids handled by HoloViews. So far, we have mainly dealt with uniform, rectilinear grids, but we can use the QuadMesh element to work with non-uniform rectilinear grids and curvilinear grids.
In order to define a non-uniform, rectilinear grid we can declare explicit irregularly spaced x- and y-coordinates. In the example below we specify the x/y-coordinate bin edges of the grid as arrays of shape M+1 and N+1 and a value array (zs) of shape NxM:
n = 8 # Number of bins in each direction
xs = np.logspace(1, 3, n)
ys = np.linspace(1, 10, n)
zs = np.arange((n-1)**2).reshape(n-1, n-1)
print('Shape of x-coordinates:', xs.shape)
print('Shape of y-coordinates:', ys.shape)
print('Shape of value array:', zs.shape)
hv.QuadMesh((xs, ys, zs))
Shape of x-coordinates: (8,)
Shape of y-coordinates: (8,)
Shape of value array: (7, 7)

Curvilinear grids#
To define a curvilinear grid the x/y-coordinates of the grid should be defined as 2D arrays of shape NxM or N+1xM+1, i.e. either as the bin centers or the bin edges of each 2D bin.
n=20
coords = np.linspace(-1.5,1.5,n)
X,Y = np.meshgrid(coords, coords)
Qx = np.cos(Y) - np.cos(X)
Qy = np.sin(Y) + np.sin(X)
Z = np.sqrt(X**2 + Y**2)
print('Shape of x-coordinates:', Qx.shape)
print('Shape of y-coordinates:', Qy.shape)
print('Shape of value array:', Z.shape)
qmesh = hv.QuadMesh((Qx, Qy, Z))
qmesh
Shape of x-coordinates: (20, 20)
Shape of y-coordinates: (20, 20)
Shape of value array: (20, 20)

Working with xarray data types#
As demonstrated previously, Dataset comes with support for the xarray library, which offers a powerful way to work with multi-dimensional, regularly spaced data. In this example, we’ll load an example dataset, turn it into a HoloViews Dataset and visualize it. First, let’s have a look at the xarray dataset’s contents:
xr_ds = xr.tutorial.open_dataset("air_temperature").load()
xr_ds
<xarray.Dataset> Size: 31MB
Dimensions: (time: 2920, lat: 25, lon: 53)
Coordinates:
* time (time) datetime64[ns] 23kB 2013-01-01 ... 2014-12-31T18:00:00
* lat (lat) float32 100B 75.0 72.5 70.0 67.5 65.0 ... 22.5 20.0 17.5 15.0
* lon (lon) float32 212B 200.0 202.5 205.0 207.5 ... 325.0 327.5 330.0
Data variables:
air (time, lat, lon) float64 31MB 241.2 242.5 243.5 ... 296.2 295.7
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...It is trivial to turn this xarray Dataset into a Holoviews Dataset (the same also works for DataArray):
hv_ds = hv.Dataset(xr_ds)[:, :, "2013-01-01"]
print(hv_ds)
:Dataset [lat,lon,time] (4xDaily Air temperature at sigma level 995)
We have used the usual slice notation in order to select one single day in the rather large dataset. Finally, let’s visualize the dataset by converting it to a HoloMap of Images using the to() method. We need to specify which of the dataset’s key dimensions will be consumed by the images (in this case “lat” and “lon”), where the remaining key dimensions will be associated with the HoloMap (here: “time”). We’ll use the slice notation again to clip the longitude.
airtemp = hv_ds.to(hv.Image, kdims=["lon", "lat"], dynamic=False)
airtemp[:, 220:320, :].opts(colorbar=True, fig_size=200)
Here, we have explicitly specified the default behaviour dynamic=False, which returns a HoloMap. Note, that this approach immediately converts all available data to images, which will take up a lot of RAM for large datasets. For these situations, use dynamic=True to generate a DynamicMap instead. Additionally, xarray features dask support, which is helpful when dealing with large amounts of data.
It is also possible to render curvilinear grids with xarray, and here we will load one such example. The dataset below defines a curvilinear grid of air temperatures varying over time. The curvilinear grid can be identified by the fact that the xc and yc coordinates are defined as two-dimensional arrays:
rasm = xr.tutorial.open_dataset("rasm").load()
rasm.coords
Coordinates:
* time (time) object 288B 1980-09-16 12:00:00 ... 1983-08-17 00:00:00
xc (y, x) float64 451kB 189.2 189.4 189.6 189.7 ... 17.4 17.15 16.91
yc (y, x) float64 451kB 16.53 16.78 17.02 17.27 ... 28.01 27.76 27.51
To simplify the example we will select a single timepoint and add explicit coordinates for the x and y dimensions:
rasm = rasm.isel(time=0, x=slice(0, 200)).assign_coords(x=np.arange(200), y=np.arange(205))
rasm.coords
Coordinates:
* y (y) int64 2kB 0 1 2 3 4 5 6 7 8 ... 197 198 199 200 201 202 203 204
* x (x) int64 2kB 0 1 2 3 4 5 6 7 8 ... 192 193 194 195 196 197 198 199
xc (y, x) float64 328kB 189.2 189.4 189.6 189.7 ... 44.79 44.29 43.8
yc (y, x) float64 328kB 16.53 16.78 17.02 17.27 ... 43.84 43.7 43.55
time object 8B 1980-09-16 12:00:00
Now that we have defined both rectilinear and curvilinear coordinates we can visualize the difference between the two by explicitly defining which set of coordinates to use:
hv.QuadMesh(rasm, ['x', 'y']) + hv.QuadMesh(rasm, ['xc', 'yc'])

Additional examples of visualizing xarrays in the context of geographical data can be found in the GeoViews documentation: Gridded Datasets I and Gridded Datasets II. These guides also contain useful information on the interaction between xarray data structures and HoloViews Datasets in general.
API#
Accessing the data#
In order to be able to work with data in different formats Holoviews defines a general interface to access the data. The dimension_values method allows returning underlying arrays.
Key dimensions (coordinates)#
By default dimension_values will return the expanded columnar format of the data:
heatmap.dimension_values('x')
array(['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'C', 'C', 'C',
'C', 'C'], dtype='<U1')
To access just the unique coordinates along a dimension simply supply the expanded=False keyword:
heatmap.dimension_values('x', expanded=False)
array(['A', 'B', 'C'], dtype='<U1')
Finally we can also get a non-flattened, expanded coordinate array returning a coordinate array of the same shape as the value arrays
heatmap.dimension_values('x', flat=False)
array([['A', 'B', 'C'],
['A', 'B', 'C'],
['A', 'B', 'C'],
['A', 'B', 'C'],
['A', 'B', 'C']], dtype='<U1')
Value dimensions#
When accessing a value dimension the method will similarly return a flat view of the data:
heatmap.dimension_values('z')
array([0.29895162, 0.48479885, 0.49131234, 0.37897975, 0.11840858,
0.1954803 , 0.37878395, 0.42782478, 0.01798074, 0.17674266,
0.33687733, 0.91774159, 0.33545438, 0.07063804, 0.53582071])
We can pass the flat=False argument to access the multi-dimensional array:
heatmap.dimension_values('z', flat=False)
array([[0.29895162, 0.1954803 , 0.33687733],
[0.48479885, 0.37878395, 0.91774159],
[0.49131234, 0.42782478, 0.33545438],
[0.37897975, 0.01798074, 0.07063804],
[0.11840858, 0.17674266, 0.53582071]])